La mesure de la performance des équipes DevOps chez ENGIE Digital ou comment nous avons automatisé les DORA metrics à l’échelle de la digital factory d’ENGIE
Retour d’expérience
Par David Henry
Chez ENGIE Digital, la « software company » du groupe ENGIE, l’équipe du CTO (Chief Technology Officer) a mis en place à l’échelle de l’organisation un système automatisé de mesure de la performance de delivery. Le passage de la théorie à la pratique a été l’occasion de se poser de nombreuses questions et de mûrir notre réflexion sur le sujet. Nous vous proposons de partager nos questionnements, nos choix et nos enseignements :
- Le choix des mesures — DORA metrics et autres — et comment les automatiser (de DORA : DevOps Research and Assessment faisant désormais partie de Alphabet/Google),
- Les bénéfices en matière de pilotage : visualiser des anomalies et des tendances, objectiver des situations et observer des effets des actions d’amélioration.
- Les effets induits : inciter à plus de maîtrise et de rigueur dans les pratiques.
Introduction
Le CTO d’ENGIE Digital, Vincent Derenty, et son équipe ont parmi leurs missions celle d’accompagner les équipes produit dans l’amélioration de leur efficacité opérationnelle. Ces équipes produit sont en charge de l’élaboration et du développement de solutions digitales stratégiques pour le groupe ENGIE. L’équipe du CTO agit auprès d’elles en tant que centre d’expertise sur les questions de cybersécurité, de méthodologies agiles, d’architecture logicielle et de pratiques de développement.
Lorsqu’il est question d’amélioration, il est rapidement question de mesure. On ne peut maîtriser et piloter son action d’amélioration qu’en sachant d’où on part, en déterminant où on veut aller, et en observant les effets de nos initiatives.
« Vous ne pouvez manager ce que ce que vous pouvez mesurer » disait Peter Drucker.
En matière de mesure de la performance des équipes DevOps, la référence est le State of DevOps report et l’analyse à laquelle il donne lieu dans l’étude Accelerate, qui démontre la corrélation entre performance opérationnelle et performance business des entreprises. La performance opérationnelle y est décrite comme relevant d’un ensemble de 24 capabilities réparties en 5 catégories : Continuous delivery, Architecture, Product and process, Lean management et monitoring, Culture. Ces capabilities sont autant de leviers d’amélioration de l’efficacité des organisations de delivery logiciel.
Convaincus de l’approche, nous avons décidé de mettre en place la collecte automatisée des données qui nous permettent aujourd’hui de calculer et de suivre les 4 mesures fondamentales (communément appelées DORA metrics) qui y sont préconisées :
- 2 indicateurs de vitesse
-Deployment frequency
-Lead time for change
- 2 indicateurs de stabilité
-Mean time to restore
-Change failure rate
Ce n’est pas tant cette prise de décision qui nous a mobilisés que sa mise en œuvre.
Le principe de ce qui doit être mesuré par chaque indicateur est clair ; ce qui l’est moins, c’est sa traduction concrète. Quelles données opérationnelles relever ? Comment les acquérir ? Comment les traiter ? sont les questions qui nous ont rapidement occupés et, comme bien souvent, nous avons constaté que le diable se cachait dans les détails.
Nous vous proposons de vous décrire comment nous sommes passés des grands principes à l’implémentation concrète de ces mesures en faisant le lien avec la réalité des pratiques opérationnelles des équipes.
Nous en profiterons également pour vous présenter quatre indicateurs supplémentaires que nous avons adjoints aux DORA metrics. Ceux-ci sont plutôt tournés vers l’état du flux de travail — flow — des équipes :
- Deployment chronology
- Activity split
- Feature flow
- Defect flow
Ici la notion de flow s’entend dans le sens de la recherche de fluidité, bien définie et illustrée par Don Reinertsen dans son ouvrage de référence Product Development Flow.
L’ensemble de ces indicateurs a été pensé dans le but de doter les équipes de moyens d’observer clairement leurs réalités opérationnelles, d’objectiver leurs situations, d’identifier des anomalies ou des tendances dans leur delivery.
Ces mesures sont mises à disposition des équipes dans une interface — un plugin Confluence — dont nous vous présenterons les écrans, Confluence étant l’outil de gestion de la connaissance le plus communément utilisé dans notre contexte.
Contexte
Une rapide présentation du contexte est nécessaire pour bien comprendre nos enjeux.
Nous l’avons dit, le centre d’expertise de l’équipe CTO d’ENGIE Digital apporte son appui à plusieurs équipes en charge de la réalisation de produits digitaux constituant pour le groupe ENGIE des avantages concurrentiels sur ses marchés. Pour la plupart, ces produits et les équipes qui les réalisent sont nés dans les différentes entités du groupe et préexistaient à ENGIE Digital où ils ont été regroupés après leur création.
- ENGIE Digital compte une dizaine de ces produits,
- Ils peuvent être réalisés par des équipes (Product management + Profils techniques) variant d’une dizaine de personnes à plus de soixante,
- Ces différentes équipes sont indépendantes et responsables. Elles décident de leurs pratiques de développement et de collaboration, de leurs flux de travail, et en partie de leurs outils et de leurs choix technologiques et architecturaux. A noter, et c’est certainement une de nos spécificités, que les pratiques de ces différentes équipes sont relativement hétérogènes du fait de leur antériorité.
Nos sources de données brutes sont les outils les plus communément utilisées par les équipes :
- GitHub (gestionnaire de sources) : qui nous permet d’être au plus proche de la vie de la base de code.
- Jira (outil d’aide à l’organisation) : qui nous permet d’être au plus proche du flux de travail des équipes.
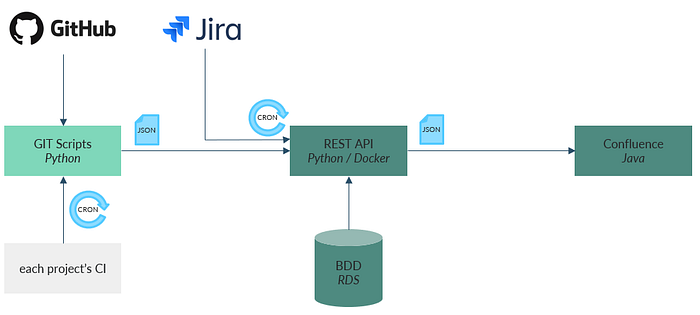
Implémentation haut niveau
Voici comment nous avons choisi de procéder.
Le cœur du dispositif est une REST API qui collecte les données :
- Poussées, lorsqu’elles proviennent de GitHub via leur usine d’intégration continue (CI) par les projets eux-mêmes grâce à des scripts à leur main.
- Tirées, lorsqu’elles proviennent de Jira par un cron.
Et qui les expose pour affichage au plugin Confluence.
Parti pris
Comme nous allons le voir, une bonne partie de la réflexion a consisté à choisir les données qui devront être traitées pour construire chacun des indicateurs.
Cette réflexion s’est tenue avec pour objectif connexe de faciliter l’adoption de notre démarche par les équipes, c’est-à-dire être les moins intrusifs et les moins normatifs vis-à-vis des pratiques préexistantes et être adaptables à leur variété. Nous avons donc essayé, sans y parvenir systématiquement, de minimiser les efforts à consentir par les équipes pour permettre la collecte des données.
C’est dans cette tension entre disponibilité, facilité d’acquisition, et précision des données que se sont jouées nos prises de décision.
Définitions, calculs et visualisation
Pour chaque mesure, l’exercice a donc été le même : passer d’une intention à une implémentation technique en définissant des calculs et des notions, et en s’assurant de rester adaptés aux pratiques et habitudes des équipes.
Voyons ce qu’il en est pour chacun des indicateurs.
1. Deployment frequency
Principe
Il s’agit de calculer pour une période la fréquence des déploiements, et donc de compter pour cette période le nombre de mises en production de nouvelles versions du produit considéré.
Ces deux notions sont structurantes pour la suite, au-delà de la Deployment frequency.
La mise en production (MEP)
Qu’est-ce qu’une MEP ? En considérant la réalité technique des architectures micro-services et des organisations multi-repository par exemple, la question qui semblait simple devient plus complexe.
La définition que nous avons retenue est la suivante : une mise en production consiste à mettre à disposition des utilisateurs une nouvelle version du produit en procédant, dans un même mouvement, au déploiement d’un ou plusieurs repositories.
Une MEP est donc à distinguer :
- D’un déploiement de repository : lorsque plusieurs repositories sont déployés au cours d’une même MEP, on considérera un seul événement « MEP ».
Ex. : Si je pousse du nouveau code en production tous les 15 jours en mettant à jour à chaque fois 5 repositories, j’aurai bien une fréquence de 2 MEP par mois et non 10 (2x5 repositories). - D’une Mise en Service (MES) : Quand bien même le nouveau code en production ne changerait pas le comportement de l’application pour l’utilisateur final (en cas de feature flipping/flags/toggles par exemple), nous considérerons un événement « MEP » pour chaque mise à jour.
Ex. : Si je pousse les différentes composantes d’une nouvelle fonctionnalité à l’occasion de 10 déploiements successifs en production sur une période d’un mois, pour finalement activer la fonctionnalité terminée lors de la dixième. Je compterai bien une fréquence de 10 MEP par mois et non 1 (qui correspondrait à la MES).
L’idée est donc bien de compter les livraisons de nouvelles versions du produit. Cette notion de version a également nécessité des efforts de définition et de mise en pratique pour permettre l’automatisation.
La version de produit
Compter les MEP consisterait donc à compter le nombre de versions de produit déployées sur une période. Mais encore faut-il effectivement versionner le produit. Ce qui peut paraitre évident ne l’est pas tant que ça.
Un de nos rares actes normatifs fut de demander de systématiquement identifier les versions en recourant classiquement au formalisme du Semantic Versioning (SemVer) : X.Y.Z où X est le numéro de version majeure, Y est le numéro de version mineure et Z est le numéro de correctif pour une version corrective. Ce formalisme commun nous permettra de facilement décompter les combinaisons X.Y.Z différentes amenées en production et d’ainsi compter les MEP.
Là encore, ce sont plutôt les organisations multi-repository qui ont nécessité notre attention car pour certaines d’entre elles, cette notion de version de produit n’existait pas. Seule la notion de version de repository existait, la version de produit restant au niveau implicite de la combinaison de versions de repositories sans faire l’objet d’une identification formelle dans les sources. Ce qui en soit pouvait être l’objet d’actions d’amélioration dans la perspective d’un besoin de restauration des systèmes dans un état antérieur.
Nous avons donc eu à proposer aux équipes concernées un mode opératoire pour taguer au moment des MEP les repositories d’une application avec un même tag annoté comportant un numéro de version incrémenté et la date de déploiement de celle-ci. Concrètement, il s’agit dans notre cas d’un job Jenkins qui est joué après les déploiements en production.
Calcul de la Deployment frequency
GitHub est notre source de vérité. Une fois mis en place le job de tagging de versions, nous compterons les différents tags de versions de produit — combinaisons X.Y.Z différentes et qualifiés par leurs dates — correspondant à une période pour connaître la fréquence de déploiement sur cette période.
2. Lead time for change
Principe
Le principe est de calculer le temps qui s’écoule entre le moment où un développement est réputé terminé et son effective mise en production. L’esprit de cet indicateur est de mesurer un délai : combien de temps un changement de code met-il à être déployé en production ?
C’est l’indicateur qui nous a posé le plus de difficulté.
Un indicateur composite
En premier lieu, il est à considérer que deux grands types de facteurs viennent influencer le temps que prend un développement à aller en production :
- L’efficacité technique : la capacité à déployer rapidement du code sur l’environnement de production, en automatisant par exemple le pipeline de déploiement ou les tests de régression.
- L’efficacité organisationnelle : les bons principes de collaboration qui minimisent le temps passé à vérifier ou attendre une vérification de conformité (revue de code, revue fonctionnelle ou une validation business), et limitent l’importance du retravail en créant les conditions d’une communication de qualité en amont des développements entre profils fonctionnels et techniques.
Le Lead time for change est donc de ce point de vue un indicateur composite qui témoigne de ces deux dimensions dans des proportions variables selon les cas. C’est en cela que ce qui est mesuré va varier d’une équipe à l’autre.
Un indicateur sensible au contexte de l’équipe
Les relations entre flux de travail, état du code source (merge sur les branches principales notamment) et environnements de déploiement peuvent fortement varier en fonction des choix organisationnels et techniques des équipes — en fonction notamment des stratégies de branching (Git flow, GitHub flow, Trunk based, etc.), de la mise en place d’un principe de review apps, de l’automatisation ou non des tests de régression et du caractère immédiat ou différé des corrections associées.
En fonction du contexte donc, de l’organisation et des possibilités d’une équipe, les différentes composantes de l’indicateur interviennent selon des modalités et à des moments différents, et seront en conséquence plus ou moins justement représentés selon ce que nous retiendrons comme point de départ pour le calcul Lead time for change.
Il est donc très important de se garder de comparer par cet indicateur des équipes aux situations organisationnelles et aux possibilités techniques différentes.
L’âge d’une version
Nous l’avons vu plus haut, ce qui va en production est une version de produit. Or une version peut comporter plusieurs incréments (User stories, corrections, etc.), souvent d’importances différentes en termes de complexité, de temps de travail, de valeur métier, etc.
Nous avons retenu le commit comme incrément de référence tel que recommandé dans la littérature. Ce qui a l’avantage de nous faire considérer des éléments unitaires cohérents du point de vue implémentation technique en nous épargnant la correspondance avec les notions plus abstraites de tâches ou de user stories.
Se pose ensuite la question de l’« âge » des versions ? Comment, sur la base des commits qui la composent, déterminer le temps qu’a pris le code réputé terminé d’une version à aller en production ?
Nous appuyant à nouveau sur la littérature, nous avons retenu que l’âge d’une version correspondait à l’âge moyen des commits qui la composent.
[RESERVE] Cette approche basée sur l’âge moyen des commits comporte certaines limites parmi lesquelles, et c’est la plus notable, le fait que des pratiques perturbatrices des flux de travail comme des corrections tardives donnant lieu à des commits sur des branches main/master auront pour effet de « rajeunir » les versions.
Par exemple, considérons un développement qui s’attarde sur une branche, réalisé dans un contexte où je suis obligé de merger pour recetter. Si 8 anomalies sont trouvées lors de la recette suite au merge de ce développement et que 12 commits sont réalisés pour les corriger, les effets de l’âge de la branche sont gommés par les commits de corrections. Dans ce cas de figure, plus les correction sont nombreuses et réalisées tardivement dans le flux de travail, plus la valeur de l’indicateur s’améliore. Ce qui est à l’inverse de ce qui est souhaité.
La piste que nous envisageons pour pallier ce phénomène est de ne plus prendre la moyenne de l’âge des commits comme âge de la version, mais le temps qui s’est écoulé entre le plus ancien des commits de la version et la MEP de la version. Les bonnes pratiques seraient ainsi plébiscitées (Stop starting, start finishing : limitation du travail en cours et du stockage de code prêt).
Calcul du Lead time for change
Manipulant la notion de commit, GitHub est donc naturellement notre source de vérité.
Calculer un âge, c’est mesurer une durée entre une date de début et une date de fin.
- La date de début que nous avons retenue pour chaque commit est la committers date(GIT_COMMITTER_DATE) qui correspond à la date de la dernière modification d’un commit (considérant que c’est la donnée qui nous rapprochait le plus de l’idée de Réputé terminé).
- Et la date de fin est la date de déploiement portée par le tag de la version de produit dans laquelle le commit est embarqué.
Il suffit ensuite de calculer l’âge de la version en faisant la moyenne de l’âge des commits qui la composent.
3. Mean time to restore
Principe
L’idée est de déterminer le temps nécessaire en moyenne pour rétablir un service en cas d’incident ; le service impacté pouvant être tout ou partie du produit considéré.
Incident
Notre définition d’un incident — en tant qu’événement devant faire l’objet d’un décompte de son temps de résolution — est liée à sa conséquence opérationnelle : si un dysfonctionnement du produit perturbe tant les utilisateurs qu’il nécessite qu’un ou plusieurs membres de l’équipe cessent séance tenante leurs tâches courantes pour s’en occuper, alors il s’agit d’un incident.
Cette définition nous permet de rester contextuels et e nous adapter aux usages et aux réalités métier de chaque équipe en la matière.
Calcul du Mean time to restore
Pour ce type d’événement, Jira est notre source de vérité. C’est en effet lui qui nous permet d’identifier dans le flux de travail les tâches (tickets) qui pourront être qualifiées d’incidents et ainsi de suivre leurs temps de résolution.
Fonder notre approche du sujet sur le flux de travail, et non sur un monitoring technique, nous permet de rester fidèles à notre définition de l’incident basée sur la perturbation des utilisateurs, et pas seulement sur des critères de disponibilité ou de performance.
Il s’agit donc pour chaque équipe de déterminer les tickets correspondant à notre définition de l’incident. Nous utiliserons pour cela dans Jira :
Ce sont des couples issueType/priority spécifiques par équipe qui identifient les tickets à considérer comme des incidents pour cette équipe.
Et pour chacun de ces tickets nous décomptons le temps s’écoulant entre la date de création du ticket (creationDate) et sa date de résolution (resolutionDate).
À noter qu’il faudra être attentif à ce que cette date de résolution (resolutionDate) soit déterminée dans le paramétrage Jira par le passage dans un état signifiant que le code a été déployé en production.
Pour une période donnée, on fera la moyenne des temps de résolution des différents incidents résolus dans la période.
[RESERVE] Les durées calculées restent indicatives, le cycle de vie des tickets dans Jira pouvant être en décalage avec la réalité opérationnelle : la date de création d’un ticket peut ne pas correspondre au moment de détection du problème donnant lieu à l’incident et encore moins à sa date d’apparition. De même, sa date de résolution ne correspondra pas nécessairement au moment exact du passage en production du correctif correspondant.
4. Change failure rate
Principe
Il s’agit de déterminer pour une période donnée la proportion de changements en échec.
Changement en échec
Capitalisant sur la mise en place du tagging de versions de produit pour décompter les MEP, nous considérons qu’une MEP correspond à un changement, et qu’un changement en échec correspond à une MEP immédiatement suivi du déploiement d’une version corrective.
Ce qui est très simple à déterminer avec le standard SemVer X.Y.Z : si Z ≠ 0 il s’agit d’une version corrective. On conclura donc que la version qui précède était en échec.
Calcul du Change failure rate
Nous nous basons sur les mêmes données que la Deployment frequency issues de GitHub.
Nous calculons la proportion que représentent les versions correctives X.Y.Z où Z ≠ 0 parmi toutes les versions X.Y.Z ayant fait l’objet d’une MEP sur la période.
Notons qu’une version corrective peut elle-même être en échec, X.Y.1 suivie de X.Y.2 par exemple. Dans ce cas on aura bien 2 versions en échec X.Y.0 et X.Y.1 et une version en succès X.Y.2 ; et donc sur cette période un Change failure rate de 2/3 (2 MEP en échec sur 3 MEP au total)
[RESERVE] On le voit dans l’exemple qui précède, sur des périodes courtes ou en cas de fréquence de déploiement faible cet indicateur peut se révéler très volatile.
5. Visualisation de la performance de delivery
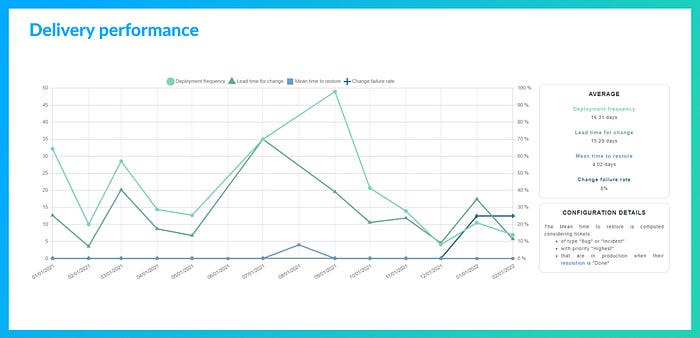
La performance de delivery des équipes se matérialise en un graph présentant 4 courbes correspondant chacune à l’une des DORA metrics. Le graph est construit à la demande sur la plage de date souhaitée par l’utilisateur avec un pas de mesure — une moyenne — pouvant être calculé à la semaine, au mois ou au trimestre.
Cette représentation permet de mettre en évidence les relations logiques qui lient les indicateurs entre eux et de donner pour la période considérée une vision globale agrégeant les différentes composantes de la performance opérationnelle.
6. Flow monitoring
En exploitant les données à notre disposition, nous avons élaboré une série de quatre indicateurs plus directement liés aux activités des équipes et à leur flux de travail (flow) et se répondant les uns les autres.
Nous avons cherché à rendre observables :
- La proportion des différentes activités de développement des équipes (Activity split)
- La chronologie des déploiements dans le temps (Deployment chronology)
- Le flux des livraisons fonctionnelles (Feature flow)
- Le flux des corrections (Defect flow)
La Deployment chronoly exploite les données issues de GitHub identifiant les différents déploiements.
En revanche, les trois autres indicateurs — Activity split, Feature flow et Defect flow — ont Jira pour source de données. Chaque type d’activité correspondant à un ou plusieurs types de ticket (issueType), et ce sont ces tickets qui sont dénombrés pour constituer les indicateurs.
[RESERVE] L’unité étant le ticket, dans des équipes où l’amplitude de granularité en termes de complexité ou de temps passé est très élevée d’un ticket à l’autre, l’approximation peut devenir délicate à manipuler.
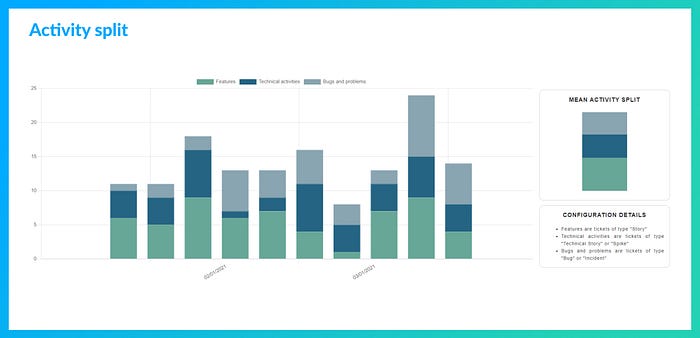
Activity split
L’Activity split suit la répartition des activités de développement regroupées en 3 grandes catégories :
- Features pour les incréments fonctionnels (User stories principalement)
- Bugs and problems pour les corrections, le support, les incidents de production, etc.
- Technical activities pour les tâches techniques : études et conception, hygiène technique, refactoring, gestion des dépendances, etc.
L’idée est de donner à l’équipe une vision de la manière dont sont répartis ses efforts et de la mettre en situation de constater si cette répartition correspond à sa stratégie ou si elle subit cette répartition : trop ou pas assez de temps passé sur les corrections, trop ou pas assez de temps passé sur de la technique, etc.
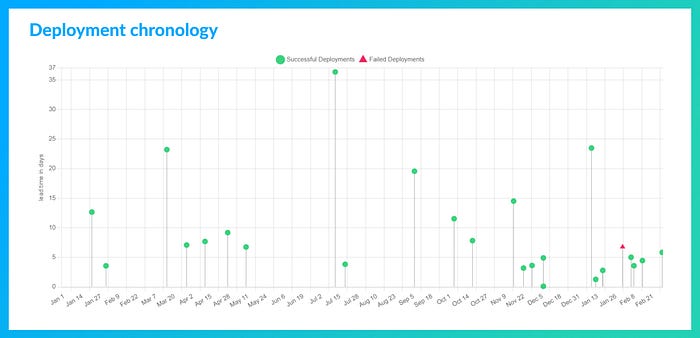
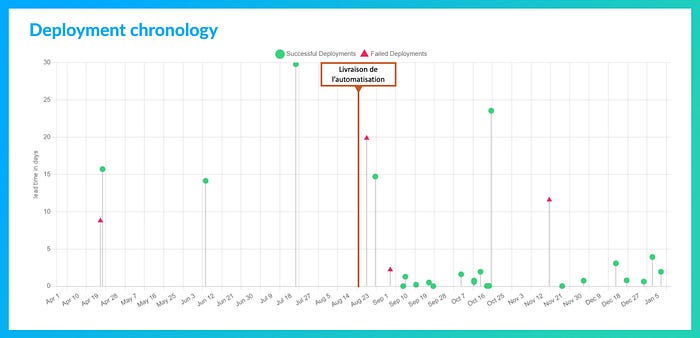
Deployment chronology
La Deployment chronology, en matérialisant dans le temps les déploiements et leurs Lead times for change, offre une visualisation granulaire des événements à l’échelle de chacun des déploiements. Cette représentation permet d’identifier les variations et accidents du rythme des déploiements en y corrélant l’âge des développements qui les composent.
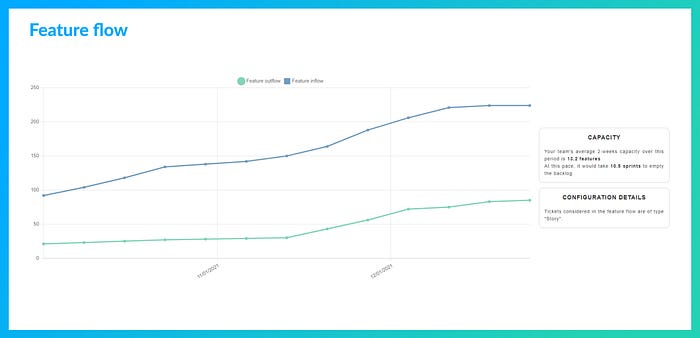
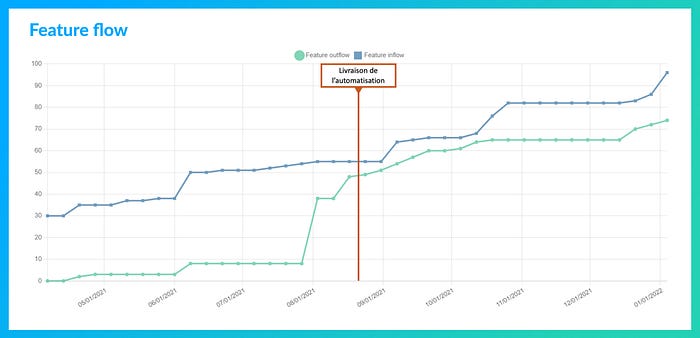
Feature flow
Il s’agit de superviser le flux de features (incréments fonctionnels) et la correspondance entre les débits entrant et sortant du système. Il permet de constater l’adéquation entre la capacité à faire et le reste à faire (non-commencés et en-cours).
Cette vision éclaire les enjeux autour de la notion de flux tiré : Notre backlog enfle-t-il démesurément et pousse-t-il notre flux ? Est-ce notre encours qui enfle ? Au contraire, notre backlog se tarit-il ? etc.
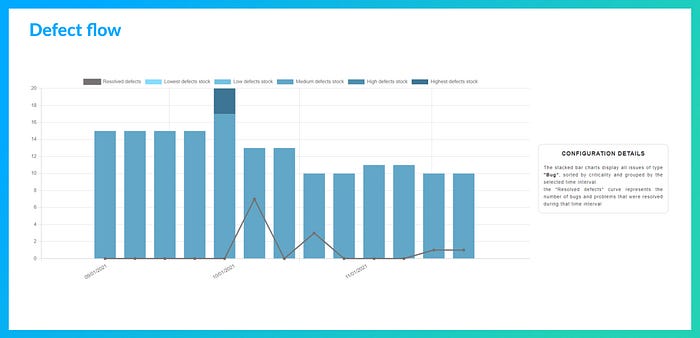
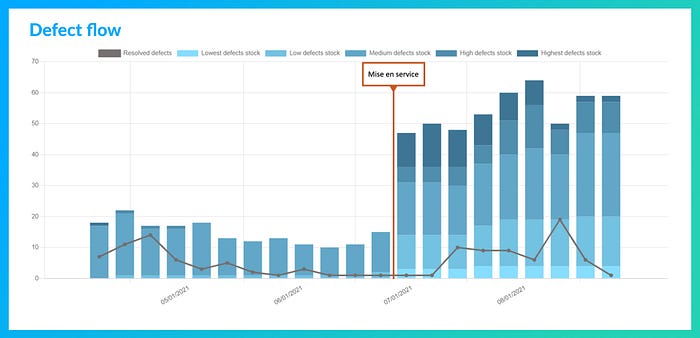
Defect flow
Nous suivons ici l’activité corrective et les effets des actions de fiabilisation en visualisant l’évolution du stock d’anomalies en regard des efforts de correction consentis. Concrètement, il s’agit de mettre en regard pour une période le nombre de tickets correspondant à des anomalies (bugs, incidents, etc.) à faire ou en cours présents à la fin de la période et le nombre de corrections réalisées durant la période, c’est-à-dire le nombre de tickets du même type qui ont été fermés.
À nouveau, il est question de gestion de flux, l’évolution du stock matérialisant les effets du débit entrant et la quantité de corrections réalisées matérialisant le débit sortant.
Cette vision permet à l’équipe de monitorer sa juste priorisation des activités de correction ou de fiabilisation.
Conclusion
Tout d’abord et c’est important de le rappeler, notamment pour les DORA metrics, ces indicateurs fonctionnent en système. Ils sont tous liés les uns aux autres, en tension. Une action ou un changement dans l’équipe fera probablement varier plusieurs des indicateurs.
Ensuite, l’observation des chiffres n’est que le début de la recherche de sens. Les chiffres donnent des indices, c’est l’inspection du contexte, des événements, des contraintes, etc. qui fournira des conclusions ou des explications et éventuellement des pistes d’amélioration.
Ces précautions prises, nous vous proposons de revenir sur les bénéfices que nous avons constatés suite à la mise en place de ces mesures, parmi lesquels nous pouvons distinguer deux types :
- Les bénéfices attendus, ceux que nous anticipions.
- Les effets induits, plus inattendus mais néanmoins notables.
Bénéfices attendus
Nous venons de l’évoquer, les principaux bénéfices attendus viennent de la vision systémique des situations des équipes que nous offrent les indicateurs. Ils nous permettent de plus simplement :
- Identifier les anomalies ou les tendances sur lesquelles investiguer.
Le graphique ci-dessous montre très bien la nécessité de revoir la quantité d’effort à allouer aux corrections suite à une première mise en service d’un produit :
- Factualiser les situations et de structurer les discussions sur les axes d’amélioration.
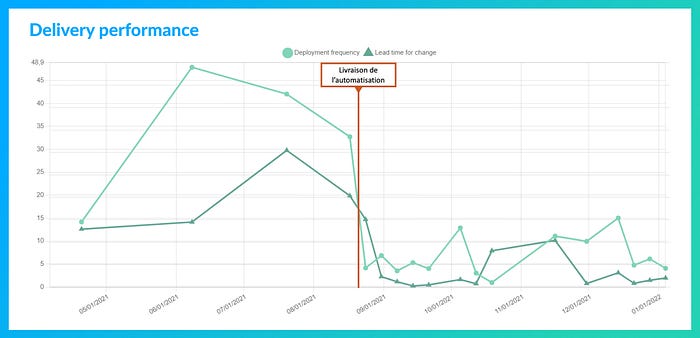
Illustration : Plusieurs équipes ont choisi de systématiquement ouvrir leurs rétrospectives par une revue collective des indicateurs afin d’y déceler d’éventuels faits notables devant faire l’objet d’actions, de discussions ou de célébrations. - Constater les effets des actions d’amélioration.
Illustration : Le graphique ci-dessous montre les effets de la livraison d’un chantier d’automatisation des déploiements, aux alentours du 20/08/2021.
Effets induits
Le processus de mise en place du système de relevé a lui-même mis en lumière certaines situations et a pu provoquer des modifications allant dans le sens de plus de maîtrise et de rigueur dans les pratiques :
- Nous l’avons déjà évoquée, la mise en place de SemVer au niveau global du produit est en soi une amélioration, permettant de mieux maîtriser la composition de la base de code en production.
- Le fait que nous nous basions, pour le Mean time to restore et le monitoring des flux, sur une notion de résolution correspondant à la mise en production du code concerné en prenant pour source d’information la vie des tickets Jira a pu faire évoluer certains workflows. Les équipes qui ne le pratiquaient pas ont fait évoluer leur système de management visuel pour y ajouter les étapes manquantes jusqu’à la production. Ce qui a permis de compléter, clarifier et prendre conscience de la réalité du flux en aval des développements.
- De même, pour l’organisation des travaux et notamment le découpage des tâches, la mise en place d’un système de décompte avec pour unité le ticket pour le monitoring des flux incite à réduire l’amplitude de granularité entre les tickets en allant vers plus de finesse ; ce qui est en soi une bonne pratique porteuse de nombreuses vertus.
- Enfin, le fait même de rendre visible un certain nombre de choses comme les stocks de defects ou le nombre d’items dans les backlogs ou l’âge de certains commits (et donc de certaines branches) a provoqué des actions de tri et de nettoyage parfois salutaires et a incité à plus de discipline quotidienne en la matière.
Conseils
Voici pour finir deux conseils qu’il nous semble important de garder en tête si vous souhaitez procéder à l’automatisation d’indicateurs — DORA ou autres — dans un contexte hétérogène comme le nôtre :
- D’abord, ne pas minimiser la phase d’exploration et prendre le temps de bien comprendre la variété des usages dans votre organisation afin de trouver le bon équilibre entre l’adaptabilité — et donc la complexité — et le caractère normatif induit par les solutions envisagées ; avec en ligne de mire l’acceptabilité et donc l’adoption par les équipes.
- Ensuite, se connecter au plus tôt aux sources de données réelles afin de vérifier l’adéquation de vos choix ou de vos hypothèses à la réalité du terrain et, bien entendu, collecter du feedback auprès de vos premiers utilisateurs ; avec en ligne de mire l’amélioration de votre solution et son adaptation à la réalité des usages.
